I. Introduction
What is expertise?
One model is that it is someone who has command of a vast library of facts, like a Jeopardy player who breezes through a category on South American capitals. A second model is success in the marketplace: a Fortune 500 CEO can be assumed to be an expert on running a business. A hybrid version is that academics, opinion columnists, bureaucrats, and others have put in years of study in a field and done whatever else is necessary to get selected into one of a small number of relevant roles, and so these are the oracles you pose your questions to.
Phil Tetlock, a UPenn professor, has built his research career around a different perspective, which I’d describe as a strong enough understanding of a subject matter’s underlying processes to accurately estimate unknown features, such as predictions of the future and counterfactual estimates [1]. He is best known specifically for proposing probabilistic forecasting as a predictive technique; if you’re really looking to demonstrate expertise in Canadian politics or the US airline industry or the state of celebrities’ marriages, then record a percentage chance of various future events and, by some metric, outscore other people who do the same. Early on in Tetlock’s career, he discovered that many experts on the Soviet Union, as they were conventionally defined, were not particularly accurate in predicting its decline and collapse. He researched the puzzle further and by the mid 2000s had found that, generally, professional experts were not much better than chance at making accurate predictions in their own field.
As circumstances would have it, the mid-to-late 2000s was exactly when a humiliated U.S. intelligence community was coming to appreciate that it ought to do a better job providing policymakers with accurate analysis of geopolitical affairs. The U.S. government, through IARPA (the Intelligence Advanced Research Projects Agency, an aspirational sibling of the renowned DARPA), funded a competition between four research groups to find ways to better predict short-term, pre-identified geopolitical and economic events.
Tetlock and his project team won the competition convincingly, and publishers bit on a book (coauthored with journalist Dan Gardner) focused on the most marketable finding that came out of the tournament: that some of the volunteers appeared to be persistently more accurate than chance, and therefore more accurate than many of the people that governments, businesses, and other organizations are relying on for analysis. If expertise is defined as predictive ability, general complex reasoning skills plus dilettante-scale subject matter knowledge seem to produce better experts than a lifelong career in the field. Consequently, improving an organization’s forecasting skills- either by emphasizing existing forecasting skills in recruiting or by strengthening the skills of current members- becomes the best strategy to improve results. Seizing on Tetlock’s choice to label the top 2% of research subjects in the Good Judgment Project as “superforecasters”, the book was titled Superforecasting and was released in 2015.
I will revisit some points from the book here.
II. Score
Tetlock emphasizes keeping score as a key element of thinking about the future. This is because he doesn’t like the current state of “predictions” as they are often made by public intellectuals:
- Predictions about economic conditions, foreign policy, and other affairs are rarely revisited. They’re done to entertain, or to look macho, or to imply that power is (or is not) in the right place.
- A related concept here is that people who Tetlock (referencing an essay by Isaiah Berlin and a long-standing dichotomy of thinking styles) labeled “hedgehogs”- those who reduce every question in some domain to one or a few priors or rules of thumb- sound more confident and make more compelling media figures than “foxes”, who are more flexible in considering the specifics of a particular question. So there’s almost a process of natural selection for the first class of pundits, but those people tend to be less accurate.
- Tetlock notes that many pundits have figured out how to state what appears to be a bold, compelling-sounding prediction without much commitment (“could” is a magic word here). Sometimes they even disguise this noncommitment in quantitative terms by labeling some longshot outcome a “40% chance” or something similar- low enough to be correct if the event does not occur but high enough to look profound in the unlikely event it does. If people remember the passage of the UK’s Brexit referendum better than they remember the failure of Scotland’s independence referendum, those who predicted change both times will be remembered as prescient; those who predicted no change both times “missed Brexit.”
By establishing a scoring system, an organization creates an expectation of accountability. If people know they will be scored for accuracy, they will focus more on accuracy compared to entertainment or tribal allegiance. And, Tetlock optimistically claims, people want to be good at forecasting. They want to improve their skills, and scoring systems perform the same function as Elo ratings in chess or a stopwatch in a track meet.
III. Superforecasters
Now we can turn to the focus of Superforecasting. The Good Judgment Project found that, in its pool of quasi-volunteer forecasters [4], top-tier scores on forecasting questions were surprisingly persistent out of sample. Tetlock writes that of the individuals designated “superforecasters”- recall this was those who fell roughly in the top 2% by accuracy- about 70% of the superforecasters from one season repeated being in the top 2% in the following season, working with fresh questions (though the domain of the questions remained geopolitical and macroeconomic events). Logically, very few superforecasters were purely lucky.
It’s not clear to me whether or not Tetlock expected an effect like this (it certainly seems like even if he did, the strength of this persistence surprised him). In any case, several chapters of the book are spent exploring several hypotheses for what might have created these superforecasters. Unfortunately, a number of possible explanations all result in weak links: for example, on average, the best-performing forecasters had only slightly higher scores on an IQ test (80th percentile on average, versus 70th percentile for the overall pool recruited by Tetlock’s team) [2].
One element that gets hinted at, but I wish had been explored more fully, is the importance of caring about performance in an irrelevant contest (maybe especially in the first season of the Good Judgment Project, when I gather participants were unaware of the potential to be designated “superforecasters”). Consider the below graph of responses to a YouGov survey [3], where Americans were asked to guess the percentage of Americans with a variety of traits:
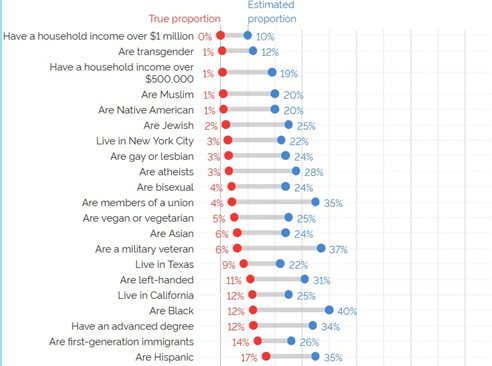
Surely very few people actually, upon a moment of reflection, believe that 12% of Americans are transgender or that 31% of Americans are left-handed (or for that matter that 20% are Native American but also 24% are Asian, and 25% are Jewish, and 40% are black, and 35% are Hispanic). These results are more likely a combination of not having a good sense of what 12% means, and not really caring about providing an accurate answer. Now imagine asking about the winner of an election in Brazil, the type of question that might have been included in the IARPA tournament. That’s something most participants carry much less context about, and is barely relevant at all.
This problem compounds further when one is thinking about very unlikely events where 5% is significantly higher than 3%- and in my experience a fair number of forecasting questions, like autocratic but internationally pressured leaders leaving power, require some degree of “OK, but *how much* lower than 10%” thought. Notice that the lowest average response, of 10%, is for people with a household income over $1 million; most Americans do not personally know someone in this category. Probability is hard! [4].
A few other notes about limitations to the superiority of superforecasters:
- Superforecasters will not predict a 50% chance of a global pandemic in the next 12 months 6 months before a pandemic begins. In fact, at that time, superforecasters will probably have a lower probability estimate than the average person.
- It’s unclear how much of superforecaster performance is general skill at “predicting the future” and how much of it is about being responsive to the constraints of forecasting tournaments. One thing I’m thinking about here is time sensitivity. Being more comfortable with and serious about probabilities probably gives a bigger advantage to superforecasters on “will China invade Taiwan this year?” than “will China invade Taiwan in the next ten years?” or for that matter “will China ever invade Taiwan?” But in some domains, such as this one, policymakers care more about the longer-term questions.
- I have no reason to believe that superforecasters or any aggregation of their forecasts can outperform liquid markets in financial assets (and I have the sense Tetlock doesn’t believe it either).
- The US intelligence community- who funded this program- wants to recruit people who are vetted on other dimensions in addition to forecasting accuracy (such as loyalty to the United States, and suitability to the intelligence community’s particular workplace conditions). It makes job offers in line with federal compensation structures, and takes the individuals it gets. Then it wants to provide techniques for honing forecasting skills or otherwise improving the accuracy of the forecasts that come out of these new hires’ analysis. “Superforecasters” were probably a disappointing result for IARPA.
IV. Aggregation: Teams and Algorithms
So far I’ve discussed what have been the most influential ideas coming out of the Good Judgment Project, but a less flashy element was its advances in how to balance information sharing and discussion against the dangers of groupthink, and in how to process the set of forecasts they received into what they would submit to IARPA.
The Good Judgment Project’s primary approach to the forecasting competition works like this: individuals enter probabilistic forecasts with a textual rationale, which is then visible to all members of a small team of other forecasters (but, in some cases, not to other teams- imagine 100 individuals, each of whom is only interacting with 9 other team members). Each rationale can then be discussed in the form of comments and replies to those comments.
This works well in part because, as we’ve established, superforecasters tend to be at least moderately motivated to care about seemingly irrelevant puzzles. So data sources and reports can get pulled in from across the Internet- team comments act as a mini-newspaper on the specific forecasting question, with both “news” and “opinion” as well as pushback. Superforecasting reports that “when a forecaster did well enough in year 1 to become a superforecaster, and was put on a superforecaster team in year 2, that person became 50% more accurate.” My read of that quote is the 50% improvement in accuracy is absolute- it does not include any compensation for reversion to the mean. And this is at the individual level.
Tetlock and his research team theorize that if you have a spread of forecasts which are somewhat independent you should then extremize their average towards zero or one. For example, if you have been able to divide your forecasters into five teams, and those “team forecasts” for some event are 62%, 67%, 70%, 71%, and 74%, then *you* should be comfortable using that information to offer a forecast of more than 70% (and maybe even more than 74%). The Good Judgment team has supposedly calibrated algorithms to do this effectively. I wish more was known about good principles in this area.
V. Long term forecasting
Recall in the second section of this essay the importance of keeping score. This imperative causes challenges for using forecasting tournaments- and maybe even the forecasting approach in general- for long term forecasting. Even if upon publishing Superforecasting Tetlock had found funding for an organization to launch a forecasting tournament asking questions about 2025, very few of those questions would have resolved as of today. Furthermore, people who gave a low probability of a Mars landing or an AI singularity or a Chinese invasion of Taiwan wouldn’t have that accurate perception included in their score yet- they’d be behind more excitable types who thought each of those outcomes was likely but also put a high probability on a pandemic killing over 1 million people.
For that matter, knowing scoring can’t be done or that it’s a long time away, it becomes much easier, even for people who have recognized ability in forecasting short-term events such as immediate elections, to make claims about the world in 20 or 30 years that are rooted more in political or philosophical ideology, or straightforward optimism/pessimism. In the long run, we are all dead- why not make some sensational forecasts for 2040, like a civil war in the United States?
Superforecasting doesn’t have much to say on this topic. The closest it gets is the idea of taking a longer-term, more nebulous question, such as US-China relations, and developing an index of shorter-term, more rigidly defined questions. These questions would be scorable, and would hopefully provide insight into the trajectory of the broader topic. However, this strategy seems out of favor today. It is hard to scale (you need to compensate forecasters for answering several questions). Also, designing forecasting questions, and how to score unforeseen circumstances, is sometimes very hard in the first place; considering that the probability of unforeseen circumstances probably increases over time, and that in this case we were only designing the questions as indicators of broader long-term trends, there are more likely to be misalignments between the intent of the question and its resolution strictly according to text.
So long term forecasting using probability estimates remains an open question (and prediction markets, another forecasting aggregation method, don’t do a good job of it either because of the time value of money).
[1] Not going to discuss counterfactual thinking in this post- will just define it as considering a sequence of events, imagining one event being exogenously changed, and then “predicting” how things would have unfolded differently (or maybe claiming the particular change is irrelevant and subsequent events wouldn’t have been different at all). Think “what if imperial China hadn’t scuttled Zheng He’s fleet” “what if Mercutio had lived” “what if Cleopatra had been ugly”.
[2] As I recall, participants were required to have the equivalent of an American bachelor’s degree or higher at the time they enrolled, though I do not think this was audited. It should not be surprising for the average IQ score of participants to be above the US average.
[4] Reviewing the history of science, probability and statistics get studied very late compared to subjects like physics (see https://en.wikipedia.org/wiki/Problem_of_points) and produce findings quite counterintuitive to our instincts (see, for example, https://en.wikipedia.org/wiki/Monty_Hall_problem).
